数学基础
📖 阅读信息
阅读时间:8 分钟 | 中文字符:3244
引言¶
图灵机、图灵测试
- 逻辑
布尔逻辑等等 - 计算
可以计算,就是要找到一个算法
哥德尔不完备定理(是否可以计算)
计算复杂性(衡量不可操作性) - 概率
使用不确定的知识进行推理
模糊逻辑和概率推理- 模糊
- 概率:贝叶斯公式
下¶
四色问题
- 蒙特卡洛树搜索:地平线搜索问题
- 深度学习神经网络
- 强化学习:学习人类的
数学推理的方面
自动驾驶
大预言模型,生成式人工智能
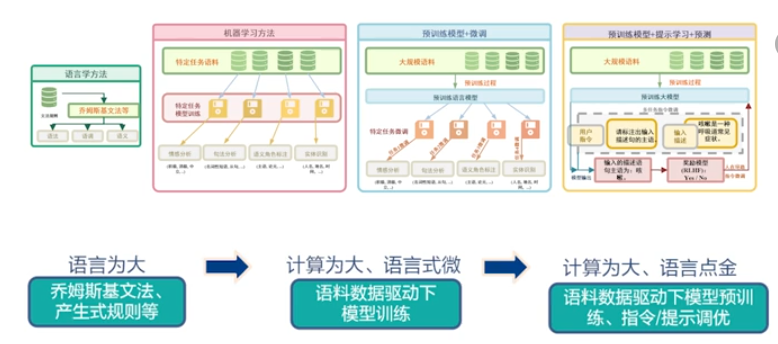
大语言模型¶
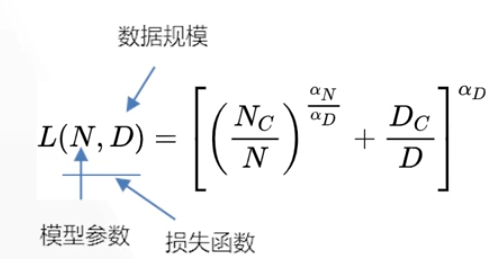
大语言模型的扩展定理:数据的驱动
问题
- 数据偏差:模型在训练中由于数据的非均衡性或者是不全面性,导致模型输出具有系统偏向性
- 训练的数据不能全面的反馈
- 技术与社会的双重属性(还有一些偏见等等)
大预言模型的幻觉:模型表面上是生成了流畅的内容,但是实际上是与客观事实不符的,逻辑矛盾的或者是完全虚构的内容
离散数学¶
集合论¶
集合论¶
表示方法:集合使用大写字母 A,B,X,Y 表示,集合中的元素使用小写字母表示
- 枚举法:
- 描述法:
- 子集
- 全集
- 空集
- 幂集:所有子集构成的集合
- 运算:
- 并集:
- 交集:
- 结合律
- 交换律
- 有序对:两个元素 a 和 b 按照顺序组成的二元组,其中 a 为第一分量,b 为第二分量
- 无序对:两个元素 a 和 b 无顺序区分
笛卡尔积是 A 和 B 两个集合所有有序对的集合
\(A\times B=\{<x,y>|x\in A\land y\in B\}\)
实际上就是变为类似二维坐标 - 二元关系:集合中两个元素之间的关系(元素直接的配对规则):
给定任意集合 A 和 B,若 \(\mathrm{R}\subseteq\mathrm{A}\times\mathrm{B}\),则 R 为 A 到 B 的二元关系,A=B 时,R 为 A 上的二元关系(函数是一种特殊的关系) - R 为有序对的集合
-
关系是有序对的集合,所以可以进行运算得到并集、交集、差集、对称差集
\[ x(RUS)y\Leftrightarrow xRyvxSy\quad x(R\cap S)y\Leftrightarrow xRy\wedge xSy\quad x(R-S)y\Leftrightarrow xRy\wedge\neg xSy\quad x(R\oplus S)y\Leftrightarrow xRy\oplus xSy \]
- 自反性:和线性代数中是比较像的—— \(R在X上自反\Leftrightarrow(\forall x)(x\in X\rightarrow xRx)\)
- 反自反性:
- 对称性:
- 反对称性
传递关系和复合关系¶
- 传递关系:\(\Leftrightarrow(\forall\mathrm{x})(\forall\mathrm{y})(\forall\mathrm{z})(\mathrm{x},\mathrm{y},\mathrm{z}\in\mathrm{A}\wedge\mathrm{xRy}\wedge\mathrm{yRz}\rightarrow\mathrm{xRz})\)
在表示可传递关系 R 的有序对集合中,若有有序对 - 复合关系:运算 "O",表示为 ROS,将两个关系联系起来:
\(\mathrm{ROS=\{<x,~z>|(\exists y)(y\in B\wedge xRy\wedge ySz)\}}\) -
逆关系:
\(\mathrm{R-1=\{<y,x>|<x,y>\in R\}}\),就是将原来关系中的 x,y 顺序调换一下
或者:\(\mathrm{xRy}\Leftrightarrow\mathrm{yR-1x}\)\[ \begin{aligned}&(1)(\mathrm{F}^{-1})^{-1}=\mathrm{F}\\\\&(2)\mathrm{~domF}^{-1}=\mathrm{ranF},\mathrm{~ranF}^{-1}=\mathrm{domF}\\\\&(3)(\mathrm{F}^{\circ}\mathrm{G})^{\circ}\mathrm{H}=\mathrm{F}^{\circ}(\mathrm{G}^{\circ}\mathrm{H})\end{aligned} \]- \((F\circ G)^{-1}=G^{-1}\circ F^{-1}\)
- 关系的闭包:设 R 是 A 上的二元关系,R 的自反闭包是关系 R ',满足:
(1) R' 是自反的 (对称的,传递的)
\((2)_{\mathrm{R}\subseteq\mathbb{R}^{\prime}}\)
( 3) 对 任 何 自 反 的 ( 对 称 的 , 传 递 的 ) 关 系 R" , 如 果 R \(\subseteq \mathbb{R^{\prime \prime }}\) , \(R^{\prime }\subseteq \mathbb{R^{\prime \prime }}\)。 记 为 r( R) ( s( R) , t( R) )
等价关系¶
- R 为非空集 A 上的二元关系。如果 R 是自反的、对称的、传递的,则称 R 为 A 上的等价关系
- 覆盖:
- 划分:
等价类¶
- 设 R 为集合 A 上的等价关系,则对于 A 中每一个元素 a,其等价的元素构成的集合为 \(\mathrm{[a]R}\),这个就是等价类,形式为:\([\mathrm{a}]_{\mathrm{p}}=\{\mathrm{x}|\mathrm{x}\in\mathrm{A}\wedge\mathrm{xRa}\}\)
这个 \(\mathrm{[a]R}\) 就是 a 的关于 R 所生成的等价类 - 偏序关系:
R 是非空集合 A 上的二元关系,如果 R 是自反、反对称、传递的,R 就是 A 上的偏序关系,记作:\(\mathrm{Y}\)
A 上有偏序关系的话,A 为偏序集,用序偶

可比与小于关系(能不能比较)
例题

谓词逻辑¶
- 命题:具有唯一真值的陈述句
- 仅有两种可能的真值——真、假
连接词¶
- 非:\(\neg\)
- 和:\(\land\)
- 或:\(∨\)
- 若……则:\(P\rightarrow Q\)
只有在 P 真 Q 假的时候这个命题才是假的,否则都是真的 - \(P\leftrightarrow Q\)
这个只有在 P、Q 的真值相同时才是真的,其余是假的 - 真值表:
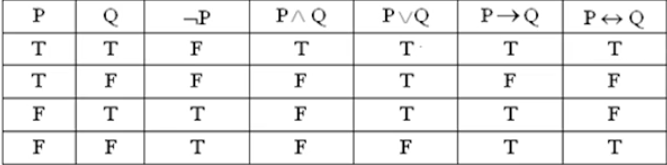
成真指派等¶
- 定义 1(成真/成假指派)
如果给定命题公式 A 的一组真值指派使得 A 的真值为真,则称该组真值为公式 A 的成真指派,反之,称为 A 的成假指派。 - 定义 2(命题公式等价)
给定两个命题公式 A 和 B,如果对于其任何一组指派而言,A 和 B 的真值都相同,则称 A 和 B 是等价的,记为 A⇔B。
常见的等价关系:

简化分析简单的命题关系
析取范式¶
- 析取范式定义:一个命题公式称为析取范式,当且仅当它具有形式:
$\(A_1 \lor A_2 \lor \dots \lor A_n \quad (n \ge 1)\)$
其中 \(A_1, A_2, \dots, A_n\) 都是由命题变元或其否定所组成的合取式。 - 示例:\((\neg P \land Q \land \neg R) \lor (P \land \neg Q \land R) \lor Q\) 是一个析取范式。
- 合取范式定义:一个命题公式称为合取范式,当且仅当它具有形式:
$\(A_1 \land A_2 \land \dots \land A_n \quad (n \ge 1)\)$
其中 \(A_1, A_2, \dots, A_n\) 都是由命题变元或其否定所组成的析取式。 - 示例:\((\neg P \lor Q \lor \neg R) \land (P \lor \neg Q \lor R) \land Q\) 是一个合取范式。
范式存在定理¶
- 定理:任意命题公式都存在与其等值的析取范式和合取范式
对于任意格式,都可以构造

谓词¶
- 定义:在原子命题中,所描述的对象称为个体;用以描述个体的性质或个体间关系的部分,称为谓词。
- 个体,指可以独立存在的事物,它可以是具体的,也可以是抽象的,如张明,计算机,精神等。表示特定的个体,称为个体常元,以 \(a, b, c\cdots\) 或带下标 的 \(a_i, b_i, c_i\cdot s\) 表示;表示不确定的个体,称为*个体变元 *,以 \(x, y, z\cdots\) 或 \(x_i, y_i, z_i\ cdots\) 表示。
- 谓词,当与一个个体相联系时,它刻划了个体性质;当与两个或两个以上个体相联系时,它刻划了个体之间的关系。表示特定谓词,称为谓词常元,表示不确定的谓词,称为谓词变元,都用大写英文字母,如 \(P, Q, R, \dots\),或其带上、下标来表示。
谓词公式与翻译¶
- 一个原子命题用一个谓词和 n 个有次序的个体常元表示成:\(P\left(a_{_1},a_{_2},...,a_{_n}\right)\),称之为该原子命题的谓词形式或命题的谓词形式
- 命题中谓词形式中个体出现的次序影响命题的真值
量词的消去规则¶
- 全称量词的消去规则:
有两种形式:
\((\forall x)\) A \((x){\Rightarrow}\) A \((c)\) ,其中 \(c\) 为任意个体常元
\((\forall x)\) A \((x)\overset{\rightarrow}{\operatorname*{\Rightarrow}}\) A \(( y)\) A \((x)\) 对 \(y\) 是自由的 - 存在量词的消去形式:
两种形式:
\((\exists x)\)A\((x){\Rightarrow}\)A\((c)\),其中 \(c\) 为特定个体常元
\((\exists x)A(x)\Rightarrow A(v)\)
这里的 A 是一个命题,命题中的变量为 x
量词的产生规则¶
- 存在量词产生规则:
\(\begin{aligned}&\mathrm{A}(c)\Rightarrow(\exists x)\mathrm{A}(x),\text{ 其中 }c\text{ 为任意个体常元}\\&\mathrm{A}(y)\Rightarrow(\exists x)\mathrm{A}(xx\end{aligned}\) - 全称量词的产生规则:
\(A(y)\Rightarrow(\forall x)A(x)\)
这里的对任意的 y 都成立
苏格拉底的论证

统计学习与回归分析¶
统计机器学习:
通过统计机器学习的方法,可以使得 ai 从历史数据中学习得到
怎么理解一些统计结论:
- 吸烟对健康是有害的,吸香烟的男性寿命减少 2250
- 不结婚的男性会减少寿命 3500 天
- 体重超重 30% 会使得寿命减少
统计学:收集、处理数据并从数据中得到结论的方法
获取数据¶
变量¶
- 变量的观测结果就是数据
- 类别变量:分类或者是定性变量
- 数值变量:分为离散变量和连续变量
描述数据¶
- 平均数:
简单平均数:\(\bar{x}=\frac{x_1+x_2+\cdots+x_n}{n}=\frac{\sum_{i=1}^nx_i}{n}\)
加权平均数:\(\overline{x}=\frac{m_1f_1+m_2f_2+\cdots+m_kf_k}{f_1+f_2+\cdots+f_k}=\frac{\sum_{i=1}^km_if_i}{n}\) - 方差:离散程度的指标
- 离散系数:标准差与响应的均值之比(对于不同组别的数据的离散程度的比较)
- 标准分数:\(\overline{z_{i}=\frac{x_{i}-\bar{x}}{s}}\)
某个数据点偏离中心的位置(除以标准差)- 切比雪夫不等式:至少有多少的数据落在平均值正负多少标准差的范围内(用于非对称的数据)
什么是概率¶
- 对事件发生的可能性大小的度量
- 介于 0-1 之间的值
- 频率随着实验次数的增大趋向于事件发生的概率
描述¶
- 期望值
- 方差
二项分布¶
n 次独立同分布的伯努利事件
泊松分布¶
正态分布¶
许多算法的误差都是符合正态分布的
卡方分布¶
独立性检验的分布
用于检验
样本统计量¶
样本统计量也具有一定的分布
中心极限定理¶
当从整体中,抽取样本时,样本均值的分布会趋向于正态分布(假设检验和置信区间的构造)
比例¶
就是局部与总体的比值
当这个二次分布的样本量很大时,也可以使用正态分布来衡量
参数估计¶
使用样本的数据估计总体的数据
- 点估计:比如直接使用样本的均值作为总体均值的估计
-
区间估计:
-
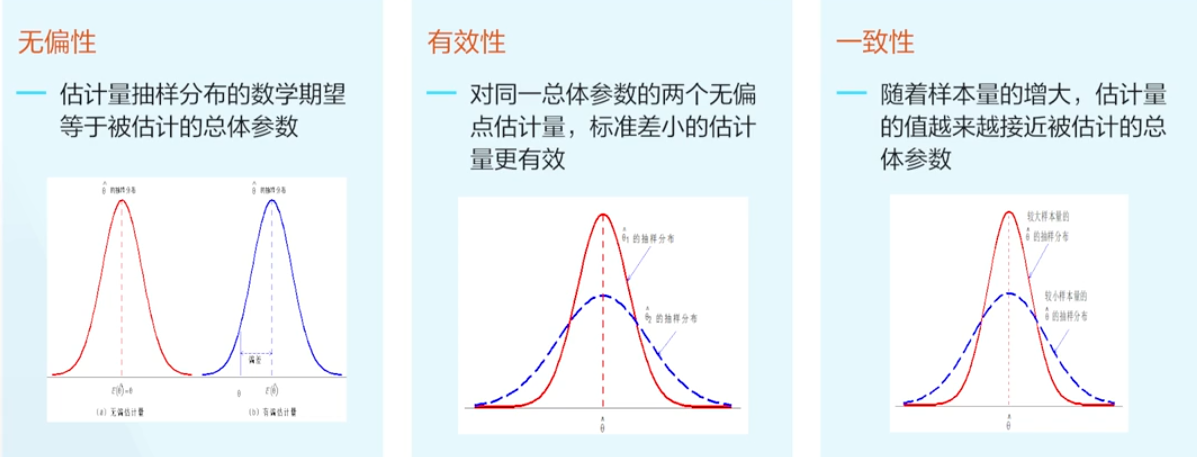
无偏性
- 有效性
- 一致性
总体均值差的估计¶
两个总体的均值差估计为:
线性回归¶
分析若干变量之间的关系叫做回归分析,刻画不同变量之间关系的模型被称作回归模型
确定了回归模型,就可以进行预测的操作
概率¶
上¶
- 最大似然估计:参数
随机试验¶
相同条件下重复进行,每次结果无法完全预测(不确定性)
关注某些特定事件发生的概率
随机事件,必然事件,不可能事件
事件间的关系:并集、交集、差集和互斥
事件间的关系¶
- 交换律:交集和并集的顺序可以交换
- 结合律
- 分配率
- 德摩根定律
频率:通过频率估计时间发生的概率(当 n 为无穷大时,频率趋近于概率)
古典概率模型¶
等可能概率模型:N 个等可能事件(比如抛硬币)
抛硬币有两个基本事件,二项随机试验
放回抽样、不放回抽样
条件概率¶
\(P(A|B)\)
全概率公式和贝叶斯公式¶
朴素贝叶斯假设:
-
条件独立在已知类别的前提下,所有特征互不影响、互不相关。公式简写:P(x1,x2,...,xn∣y)=∏i=1nP(xi∣y)
-
为什么叫 “朴素”?这个假设是简化近似,现实中特征大多不独立,但强行假设独立后,计算量暴降、模型极快,所以叫朴素(Naive)。
使用贝叶斯分类器:假设独立,降低计算的复杂性,使用对数计算乘积,可以通过测试集验证这个假设
事件的独立性¶
下¶
极大似然估计¶
找到最有可能产生这个结果的模型参数(已知样本,反推出哪个参数最合理)
贝叶斯网络¶
通过条件概率分布来量化节点间的依赖性
贝叶斯网络为有向无环图
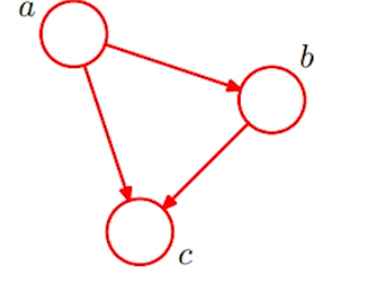
基于贝叶斯网络的概率推理:诊断、预测、分类(似然估计)
推测不确定的部分
例子
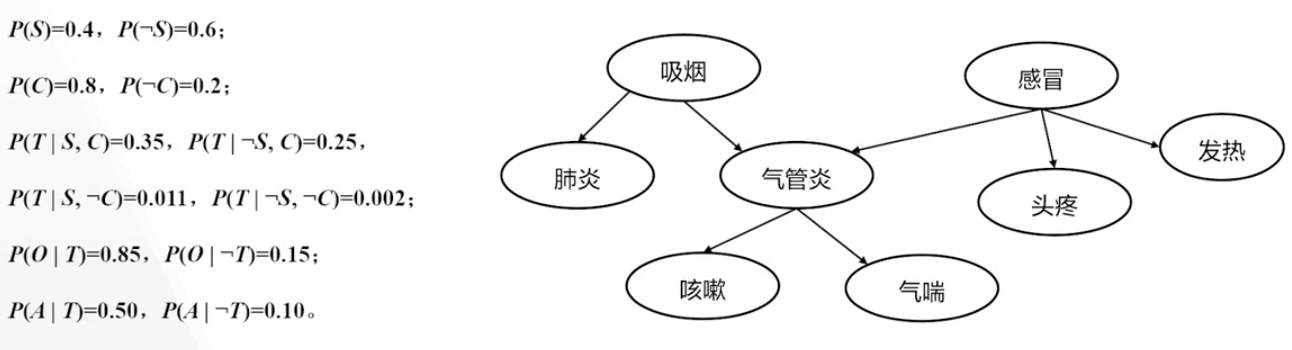
- 因果推理:由上而下推理:已知吸烟(S),计算患有支气管炎(T)的概率
- 诊断推理:由下而上推理:假设患了支气管炎,计算吸烟的后验概率:
\(P(S\mid T)=\frac{P(T\mid S)P(S)}{P(T)}=\frac{0.2822\times0.6}{P(T)}=\frac{0.16932}{P(T)}\)
\(\frac{0.16932}{P(T)}+\frac{0.8016}{P(T)}=1\)
由贝叶斯网络可以推导出因子图:
- 将节点视为一个变量,为每个变量定义一个因子
- 创建因子图中的因子节点
特殊的因子图:马尔科夫链(只取决于上次的)
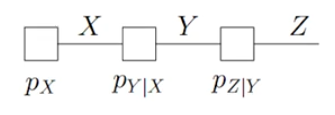
- 边缘分布:\(\begin{aligned}\bar{f}_{k}(x_{k})&\overset{\triangle}{\operatorname*{=}}\sum_{\begin{array}{c}x_1,\ldots,x_n\end{array}}f(x_1,\ldots,x_n)\\&\mathrm{except~}x_{k}\end{aligned}\)
微积分¶
导数与积分¶
集合与映射¶
设集合 A,B,按方式 f 存在唯一的 y 与之对应,则称 f 为 A 到 B 的一个映射
双射:y,x 都可以互相映射
函数:(实数集到实数集)
函数的极限¶
当 x 充分靠近 \(x_0\) 时,相应的函数值充分靠近 \(A\)
连续函数¶
导数¶
可导点的导数值为:
导函数:(在某一区间上都可导)
例子
求 sigmoid 函数 \(y\left(x\right)=\frac{1}{1+e^{-x}}\) 的导数
定积分¶
上述为牛顿莱布尼兹公式
中¶
梯度¶
多元函数
偏导数:¶
该多元函数函数的偏导数
链式法则:
方向导数¶
\(l=MM_0\)
计算公式为:
所以某点的方向导数的最大值为该点的梯度 \(|gradf|\) 的模长
- 梯度是一个向量场
梯度下降法¶
用于优化目标函数的迭代算法,通过沿着负梯度的方向更新参数来逼近目标函数的最小值
步骤
- 初始化参数和学习率
- 计算目标函数在当前参数值处的梯度
- 沿着负梯度方向更新参数 \(w^{\prime}=w-\eta\cdot\nabla f\)
- 重复 2,3
- 批量梯度下降
- 随机梯度下降
- 小批量梯度下降
误差反向传播¶
定义¶
学习的是模型的参数,所以模型的参数怎么更新
偏导数的计算¶
实质是将神经网络看做一个复合函数
对损失函数利用链式法则从输出端到输入端对各个参数求偏导的过程就是误差反向传播过程
例子
\(f(w_0,x_0,w_1,x_1,w_2)=\frac{1}{1+e^{-(w_0x_0+w_1x_1+w_2)}}\) 的误差反向传递的过程
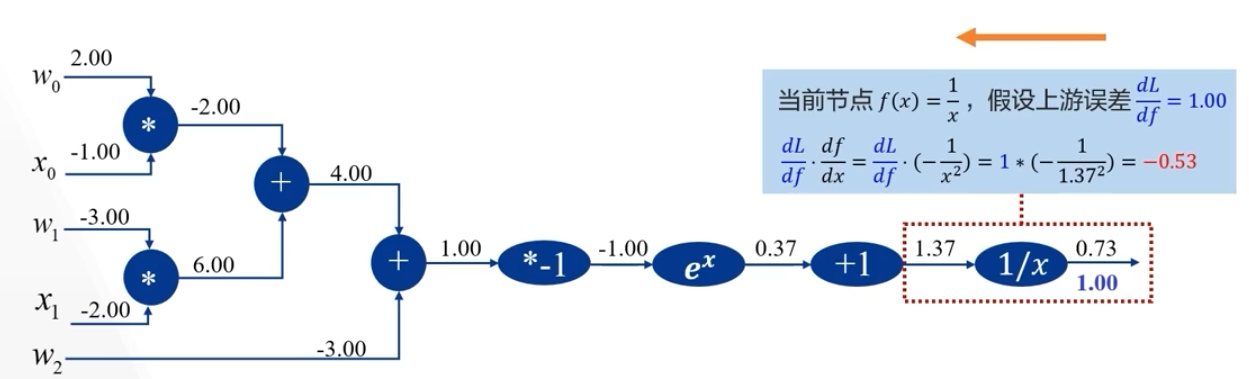
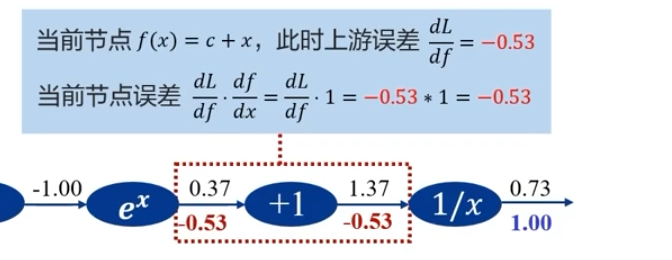
类似这种分路:
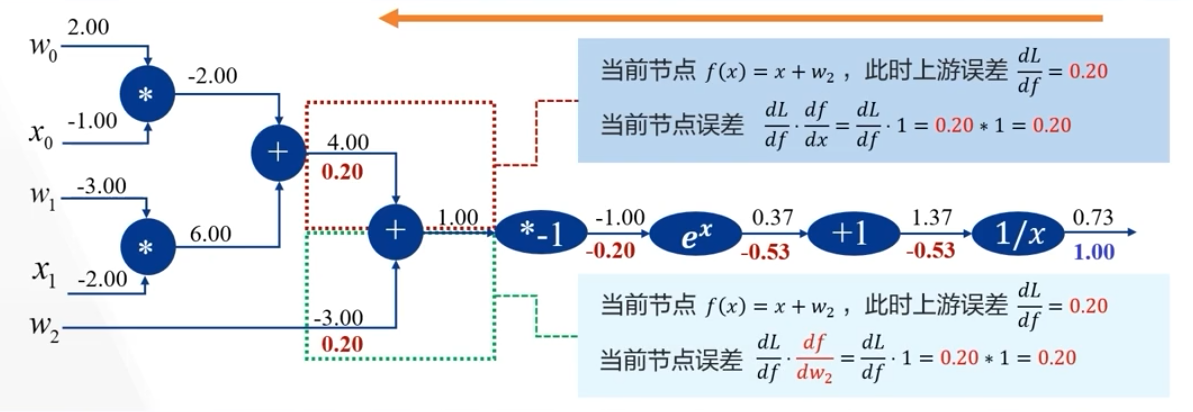
在神经网络中:
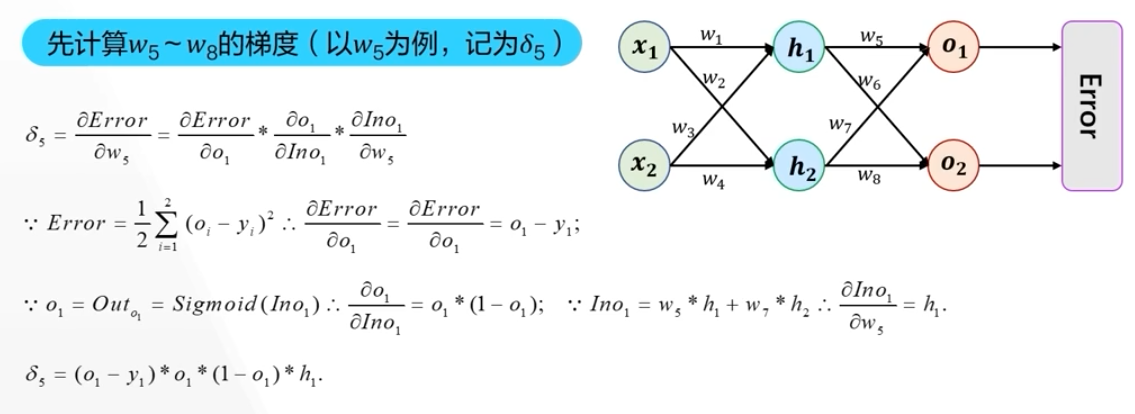
隐藏层,输出层,误差函数为:
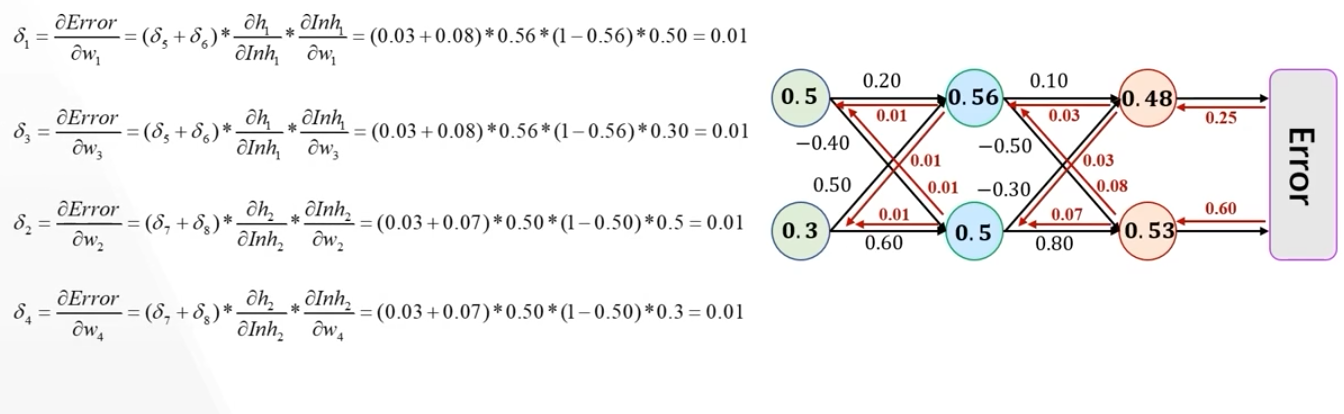
实际上就是计算误差关于某个参数的偏导(输出层、隐藏层),计算出来这个偏导之后,就可以使用梯度下降法更新参数了(\(w_1,w_2\) 这些参数)
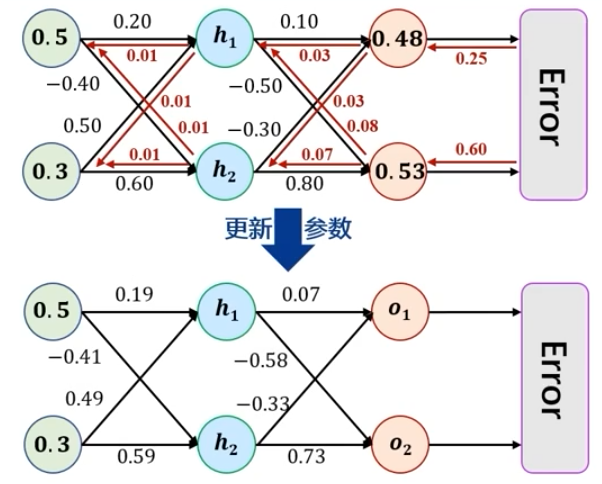
- 这里的 \(\eta\) 为学习率
- \(\delta\) 为计算出的误差
线性代数¶
矩阵¶
向量¶
大小长度和方向的量
- 加法
- 数乘
- 内积(余弦)
矩阵¶
- 加法(尺寸相同)
- 数乘
-
乘法:
\[ C=\begin{pmatrix}c_{11}&c_{12}&\cdots&c_{1p}\\c_{21}&c_{22}&\cdots&c_{2p}\\\vdots&\vdots&\ddots&\vdots\\c_{m1}&c_{m2}&\cdots&c_{mp}\end{pmatrix},\text{其中}c_{ij}=a_{i1}b_{1j}+a_{i2}b_{2j}+\cdots+a_{in}b_{nj} \] -
转置
-
矩阵的行列式
\[ |A|=\sum_{j_1j_2\cdots j_n}(-1)^{\tau(j_1j_2\cdots j_n)}a_{1j_1}a_{2j_2}\cdots a_{nj_n} \]是通过逆序数定义的
机器学习中的矩阵:
transformer 内部计算:
先将文本转为向量

- 对称矩阵:在 PCA 中会用到
- 单位矩阵
- 零矩阵
- 可逆矩阵
矩阵分解¶
线性方程组的解¶
使用的是高斯消元法
还可以使用矩阵求逆法:
特征值和特征向量¶

矩阵分解¶
- 三角分解
- 正交三角分解
- 奇异值分解(SVD)分解:图像压缩,主成分分解
- 特征分解(谱分解)
- cholesky 分解:
- 非负矩阵分解
通过分解来降维、提取隐特征、补全缺失值
主成分分析¶
广泛用于特征提取
在很多的问题中,数据中具有高维特征,使得数据在压缩后保留主要 的信息
- 将高维映射到低维的空间中
尽量保留主要的特征
找到主轴:
贡献度¶
第 k 个主成分的贡献度:\(\text{主成分的贡献度}=\frac{\lambda_k}{\sum_{i=1}^n\lambda_i}\)
- 将数据标准化处理
- 利用标准化的数据计算协方差矩阵
- 计算协方差矩阵的特征值和向量
- 计算主向量(特征值大的向量,特征值贡献度加起来要大于 95%)
- 将原来的数据在主向量上进行投影
数据偏差¶
上¶
影响,模型学习的真实性——模型偏差
方差¶
泛化误差
- 偏差:预测值与真实值之间的差异(线性回归)
- 方差:预测值之间的关系(深度神经网络),过高时,过拟合了
一般来说,简单模型(欠拟合)有一个较大的误差和较小的方差
复杂模型(过拟合)有一个较大的方差和较小的误差
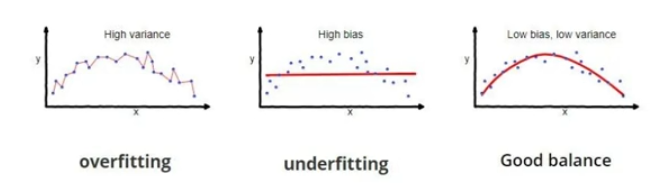
偏差的方差的窘境
- bagging:分不同的子集,降低方差
- boostinig:迭代算法,偏差会不断降低
数据偏差¶
- 采样偏差:当数据样本不具有代表性时
- 选择偏差:选择的样本不具有代表性
- 测量偏差
- 时间偏差:
- 系统偏差:有研究者或者受试者引起的对关联的不正确的
指标:
- 相对危险度:\(RR=\frac{\mathrm{a/(a+b)}}{c/(c+d)}\)
- 比值比:OR 比
- 选择偏差:收集数据时没有实现随机化
- 抽样偏差:随机化
- 收敛偏差:具有代表性的方式
- 参与偏差:参与差距
幸存者偏差
- 信息偏差(观察偏差):数据代表性和选择数据的公正性
- 误分类偏差:被错误的分类
无差分误分类偏差:倾向于最小化差异,通常低估结果- 差分误分类:准确记忆曝光的差异
- 记忆偏差:
- 采访者偏差:采访者的不同态度,采访者的中立性和一致性
下¶
数据混杂¶
由于一些其他的因素在两个组中分布不均(混杂不均)

- 统计相关性不代表因果性
- 混杂因素造成选择偏误的原因
- 第三方的因素分配不均
潜在因果分析¶
控制结果与干预结果
不存在不可策略的混杂因素
可忽略性
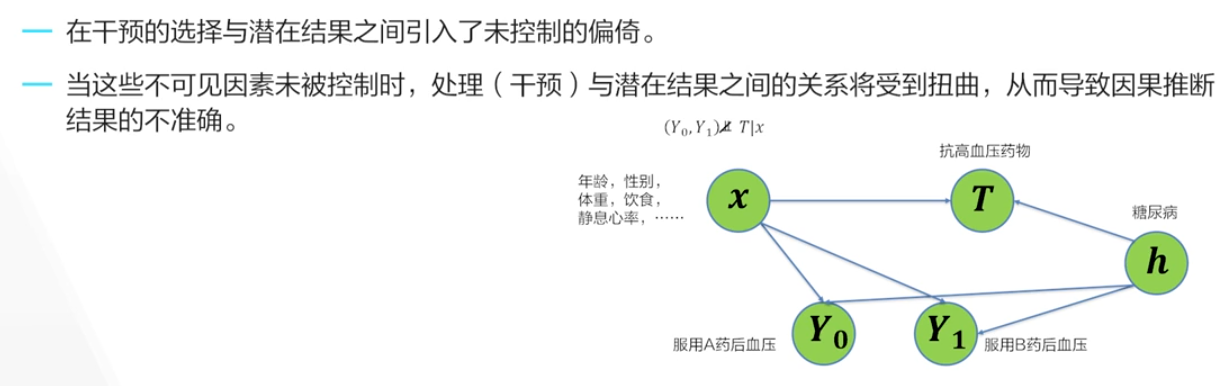
研究者尽可能控制这些不可见的因素
平均干预期望值:
倾向评分,确保产生的差异完全是由干预引起的
倾向得分是指个体接收某一干预的概率
控制混杂变量,实现类似随机试验的结果
例子

因为两个组的对象有着很大的混杂变量的差异
PA 最临近匹配
工具变量:比如烟草税的方法(烟草税只影响吸烟的行为,而不会影响其余的混杂的因素)
因果学习¶
上¶
因果关系
因果推理:分组分析的重要性
某种第三方的因素会影响最后的结果
因果推断比统计推断更进一步
结构因果模型¶
通过潜在结果描述因果关系
- 外生变量
- 内生变量
联合概率分布:
也是链式分布
因果图¶
链结构¶

链式结构
- 条件独立
分连结构¶
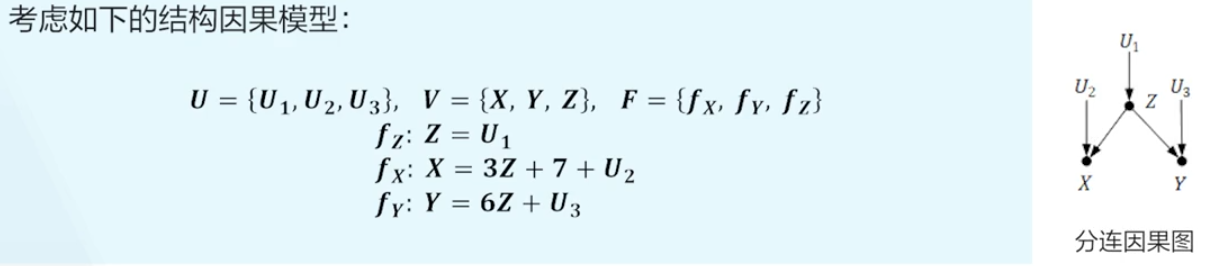
在给定 Z 时,Y 和 X 是条件独立的
汇连结构¶
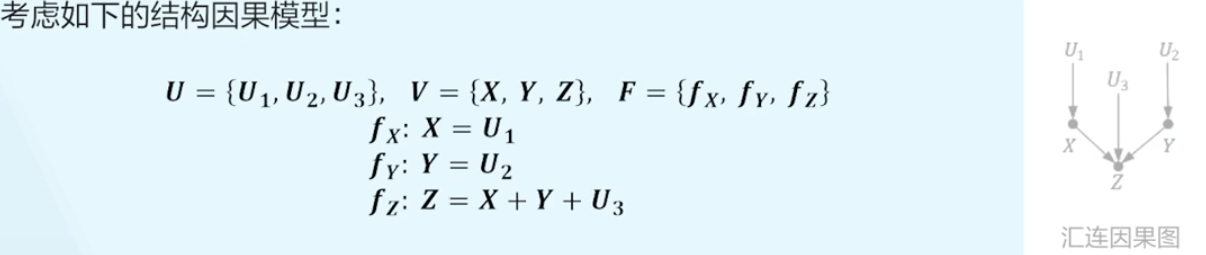
所以在汇连结构时,给定 Z 时,X 和 Y 是相关的
D 分离¶
- 有向连接
- 有向分离
复习¶
描述性统计¶
- 平均值:简单平均数、加权平均数(消除随机波动,易受极端值的影响)
- 方差:\(s ^ { 2 } = \frac { \sum _ { i = 1 } ^ { n } ( x _ { i } - \bar { x } ) ^ { 2 } } { n - 1 }\)
- 标准差:对方差去开方
样本均值¶
统计量是否无偏
样本均值的期望等于总体均值(\(\mu\))
方差¶
方差的➗️的是 \(n-1\)
因为:
样本相比于总体均值,更加聚焦于自己的样本均值
所以使用样本的差的平方估计方差是偏小的
所以可见,我们使用样本均值计算的差的平方的期望实际上是 \((n-1)\sigma^2\)
这才是无偏估计
奇异值分解¶
分解得到的两个不总是可逆的(分解的方式不同)

辛普森悖论¶
学习的科目就是一个混杂因素,不能达到一个正确的相关性的结果
贝叶斯公式¶
\(P(A)\) 为先验概率,\(P(A|B)\) 为后验概率(就是知道 B 之后 A 的概率)
例题¶
两个函数的导数相等,两个函数相差一个 C 常数
- 点估计的精确度更高
-
置信水平越高,置信区间越宽(就是 95% 置信水平的概率,真值会落在我的置信区间范围内;所以想要水平越高,区间得越宽)
-
贝叶斯网络是有向无环图
- 可以表示连续性随机变量
-
贝叶斯网络是不确定性概率推理模型。降低不确定性
-
梯度是损失函数上升最快的方向,参数沿着负梯度方向更新,减小损失
-
随机得分,模拟随机对照试验,实现伪随机分配
谓词逻辑¶

